Microsoft开源了零冗余优化器版本2(ZeRO-2),这是一种分布式深度学习优化算法,可根据集群大小进行超线性扩展。与以前的分布式学习技术相比,Microsoft使用ZeRO-2培训了10倍的1000亿参数自然语言处理(NLP)模型。
程序经理Rangan Majumder和杰出的工程师Wang Junhua在博客中写道,描述了该算法及其实验。ZeRO-2是Microsoft开源DeepSpeed库的一部分,用于深度学习培训优化。ZeRO-2优化了训练过程中的内存消耗,允许对多达1,700亿个参数的模型进行分布式训练。该算法还减少了分布式集群中工作节点之间的通信,实现了超线性并行加速,从而将培训时间减少了多达10倍。DeepSpeed团队在1,024个GPU的集群上使用ZeRO-2,达到了创纪录的44分钟的时间来训练BERT自然语言模型,比NVIDIA的结果提高了30%以上。
NLP研究的最新趋势表明,通过在较大数据集上训练的较大模型,可以提高准确性。OpenAI提出了一套“缩放定律”,表明模型精度与模型大小具有幂律关系,并且最近通过创建具有1750亿个参数的GPT-3模型对该想法进行了测试。由于这些模型太大而无法容纳单个GPU的内存,因此对其进行训练需要一堆机器和模型并行训练技术,以在整个集群中分配参数。有几种实现有效的模型并行性的开源框架,包括GPipe和NVIDIA的Megatron,但是由于集群节点之间的通信开销,它们具有次线性加速,并且使用框架通常需要模型重构。
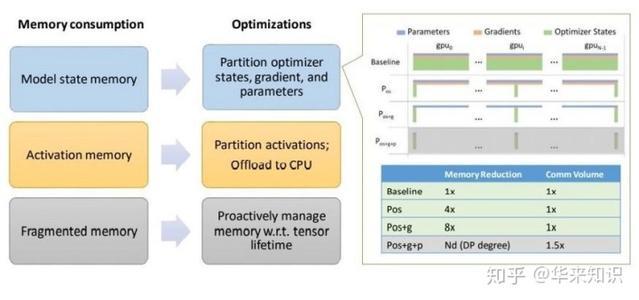
ZeRO-2使用以下三种策略来减少训练所需的内存:减少模型状态内存需求,将层激活卸载到CPU以及减少内存碎片。ZeRO-2可以通过在并行进程之间划分梯度和参数,将模型状态内存需求减少多达8倍。层激活值是从前向训练过程中保存的,以便稍后在后向过程中使用,但是ZeRO-2将它们暂时从GPU的内存移动到主机CPU的内存。最后,即使可用内存不连续,即使内存可用,内存分配也可能失败。ZeRO-2通过为连续用途(例如激活和渐变)预先分配连续的内存块来减少碎片。